AI English Exams Destroy Lives
How universities and governments around the world decide the futures of ordinary people based on questionable science and ethics
Close your eyes for a moment and imagine that you’re excited. Excited about the future. Because you’re about to start a new life. In a new country. The only thing standing between you and this new future is an English exam. But it’s not a problem, because you are a native English speaker, and also an academic: you have two university degrees. So, you do the exam, and wait for the results. And when you get your results, you are shocked to discover that you have failed the exam. The application for your new future is rejected, and you are left to ask yourself, ‘how is this possible?’
It’s not only possible, but it’s a true story. Irish veterinarian Louise Kennedy, a native English speaker with two degrees, failed the oral proficiency section of the Pearson Test of English. It’s possible because not a single human being was involved in the process of assessing her English. It was all done by computers.
And it’s a disturbing example of how governments and universities all over the world allow private companies to make millions of dollars deciding the futures of ordinary people based on questionable science and dubious ethics. Let’s take a closer look at the world of AI English testing.
AI testing is no panacea
High-stakes English exams like the Pearson Test of English (PTE) and the TOEFL iBT hold a lot of power. They are accepted by thousands of universities worldwide, including Harvard and Cambridge, and are also accepted by the US, UK, Canadian, and Australian governments for visa and immigration purposes. They are 100% computer-based tests that use machine learning, or AI, to grade the exams. And this is one of the key selling points of the exams: AI.
For example, according to the Pearson and TOEFL websites, and their YouTube videos, this is why these exams are just so damn good. This is explained on the Pearson website:
“As a result of our processes and technology, the computer behaves like an expert human examiner — but without any possible bias, lack of concentration or variation between individual examiners.”
It’s a great sales pitch, and on the surface it makes sense: computers don’t judge. So the test should be the fairest way to objectively rate your English. But there’s just one thing: it’s a total lie. In fact, it’s probable that these exams are the most unfair and biased way to measure your English ability.
It is true that computers don’t judge. They follow instructions given to them by humans. And that is the root of the problem: humans. Humans are biased, sometimes openly and consciously, but mostly completely subconsciously. And so when humans create instructions for computers to follow they introduce those biases. And then along comes AI and makes the problem worse: it amplifies those biases.
AI amplifies biases, not eliminates them
Bias amplification in machine learning is a known problem, and a very difficult problem to solve, and some of the most advanced companies in the world have fallen victim.
In March 2016 Microsoft launched a chat bot on Twitter designed to have conversations, and within hours it was tweeting racist, homophobic, and misogynistic language.
In July 2016 it was proven that Google Translate was misogynist: choosing male pronouns for doctors and hard workers, and female pronouns for nurses and lazy people.
In October 2018 Amazon closed down their AI recruitment assistant after it was proven to be sexist, preferring male applicants for most roles.
And in a more serious example from May 2016, AI software used by the US government incorrectly predicted that black people were 77% more likely to commit a crime in the future, compared to white people.
All of these biases did not come from malicious intent or sloppy programming. They came from the input data. And the AI picked up on those biases and amplified them. So saying that an AI test is ‘without any possible bias’ is pure deception.
AI is only as good as its training
Now that we know the importance of input in AI, let’s ask a really important question: who are the people who trained the AI, and how do we know they really are unbiased? Let’s look specifically at the PTE.
This paper published by Pearson explains how they obtained their input data. In September 2007 and May 2008 they performed field tests to validate and train their automated scoring systems. The training was overseen by seven supervisors: five from the UK and two from the US, as well as 95 raters, 80 from the UK and 15 from the US.
That means that there was only 102 people in total, all British or American, deciding how to score every single PTE exam. But it gets worse. The paper goes on to explain:
“To successfully complete the training, supervisors and raters had to achieve 80% adjacent agreement in the qualification exam at the end of the rater standardization training.”
This means that if the raters disagreed too much with the supervisors, they were eliminated from the training process. So, essentially, the entire PTE AI training was guided by just seven people: five from the UK and two from the US. Only seven people from just two countries at the core of an exam ‘without any possible bias’.
The vacuum of evidence
Since these exams are so important in making or breaking people’s futures, and since they are so widely accepted by both public and private institutions, it’s really important to ask what actual evidence exists that these AI English tests are truly unbiased? Thankfully Pearson have made lots of research available on their website, so we can evaluate their claim.
First, some important disclosure: Of the 40 research papers listed on their site, 27 of them are not peer-reviewed and are self-published by Pearson employees. The remaining papers (some of which are peer-reviewed) that are publicly available have all been paid for by Pearson grants.

The Pearson researchers discovered bias in the test, but no further information was provided ‘for security reasons’.
Now for the unbelievable part: one of the papers published by Pearson themselves did actually discover gender bias in the PTE, but Pearson couldn’t give the researchers any additional information about the possible source of this bias ‘for security reasons’. Remember that this is a test they claim is ‘without any possible bias’.
I performed a fairly comprehensive search outside the Pearson website for some independent peer-reviewed research about the AI that is used in the PTE. And I found nothing.
And this is the first thing that should worry anyone who has a genuine interest in fairness and equality: universities and governments all over the world handing control of people’s futures to private corporations, based on nothing but unproven marketing claims.
The speaking exam that can’t listen
It‘s important to remember that these tests are 100% computer-based, so that means that the AI has to use voice-recognition technology to assess your speaking. The Pearson website claims that:
“What this means is that you’re graded only on what you say, not your accent or anything else.”
In theory, the claim seems sensible. But anyone who has used a voice assistant like Alexa, Siri, or Google Assistant knows just how limited they are.
In 2018 The Washington Post tested 70 different commands using smart speakers and they discovered that the average accuracy was 83% for Google Home and 86% for Amazon Echo, with a huge difference in accuracy between native and non-native speakers.
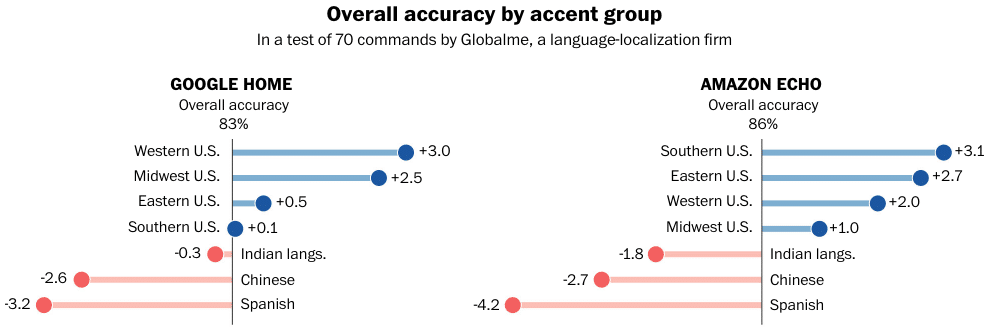
People with non-native accents faced the biggest setbacks. In one study that compared what Alexa thought it heard versus what the test group actually said, the system showed that speech from that group showed about 30% more inaccuracies.
A Stanford study from February 2020 showed that five major voice-recognition systems misidentified words about 19% of the time with white people. With black people, mistakes jumped to 35%. About 2% of audio snippets from white people were considered unreadable by these systems. That rose to 20% with black people. And these are native English speakers.
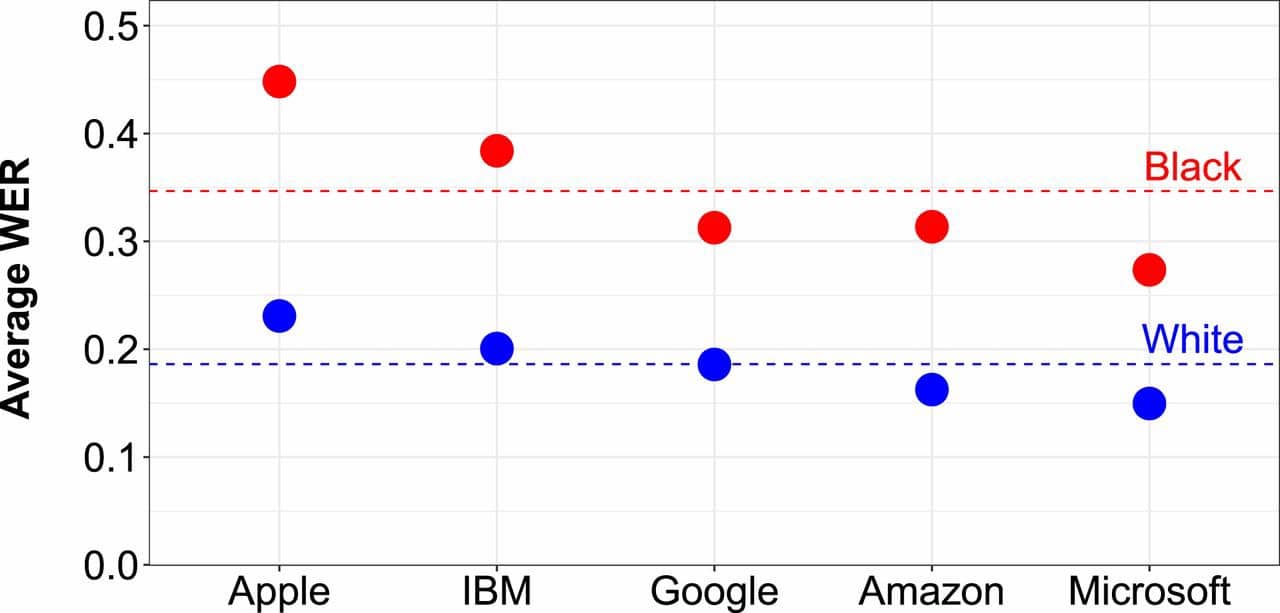
The average Word Error Rate (WER) was 0.35 for of black speakers, as opposed to 0.19 for white speakers.
According to data scientist Rachael Tatman voice recognition works best for “White, highly educated, upper-middle-class Americans, probably from the West Coast”. Not exactly the type of people that are taking an English exam. Again we see that it’s all about human bias from the data that is used to train the AI.
These Silicon Valley tech giants are spending a combined 10% of their annual research-and-development budgets, more than $5 billion in total, on voice recognition. Ask yourself this: Is it likely that Pearson or TOEFL has better voice recognition technology than Google, or Apple, or Amazon? And would you trust Siri, or Alexa to decide your future? Again, ask yourself if it’s really fair for governments and universities to be using this type of technology to decide people’s futures.
AI doesn’t understand meaning
The PTE uses a technology called the Intelligent Essay Assessor, and the TOEFL exam uses e-rater. And empirical research shows that the scores these two systems produce generally agree with each other. But there’s a problem. These systems don’t actually understand what you write. These technologies might have fancy names but their ability to look at meaning is extremely limited. All they can do is look at how the words you use relate to each other, and relate to the exam question. And so they can easily be fooled.
Les Perelman tested the the Babel Generator on a variety of Automated Essay Scoring platforms and the gibberish it generated consistently achieved high scores.
Dr Les Perelman, Director of Writing Across the Curriculum for 26 years at MIT, was so angry about the use of automated scoring systems that he wrote a computer program called Babel. Basically you enter three key words and with a click of a button it produces an essay. The essays it produces make absolutely no sense, but because it uses the right type of words you can use it to get consistently high scores in automated tests, which is something that you could never do with a human examiner.
There’s one final thing about removing humans from the meaning equation: a lot of communication is non-verbal. Pauses, facial expressions, hand gestures, eye gaze, posture, all of these things are essential parts of communication, and computer-based tests consider none of them.
Now it might seem like I am unfairly picking on specific exams, when there are others such as IELTS that offer a similar product. Those other exams are far from perfect, but at least they have the decency to provide the one thing that language is based on: a human being.
The ethics of AI English testing
I want to finish by talking about a much larger question: which is the usefulness and ethics of this type of testing.
Many people believe that English for Academic Purposes (EAP) tests are a valid barrier to entry to university. Clearly students need a sufficient level of English for what they want to study, but these high-stakes exams are not doing their job of accurately measuring language ability. Not only do teachers and administrators feel that the current system of language testing is not working, but year after year, English native speakers are outperformed on these tests by non-native speakers, showing a huge gulf between the reality of language ability and test results.
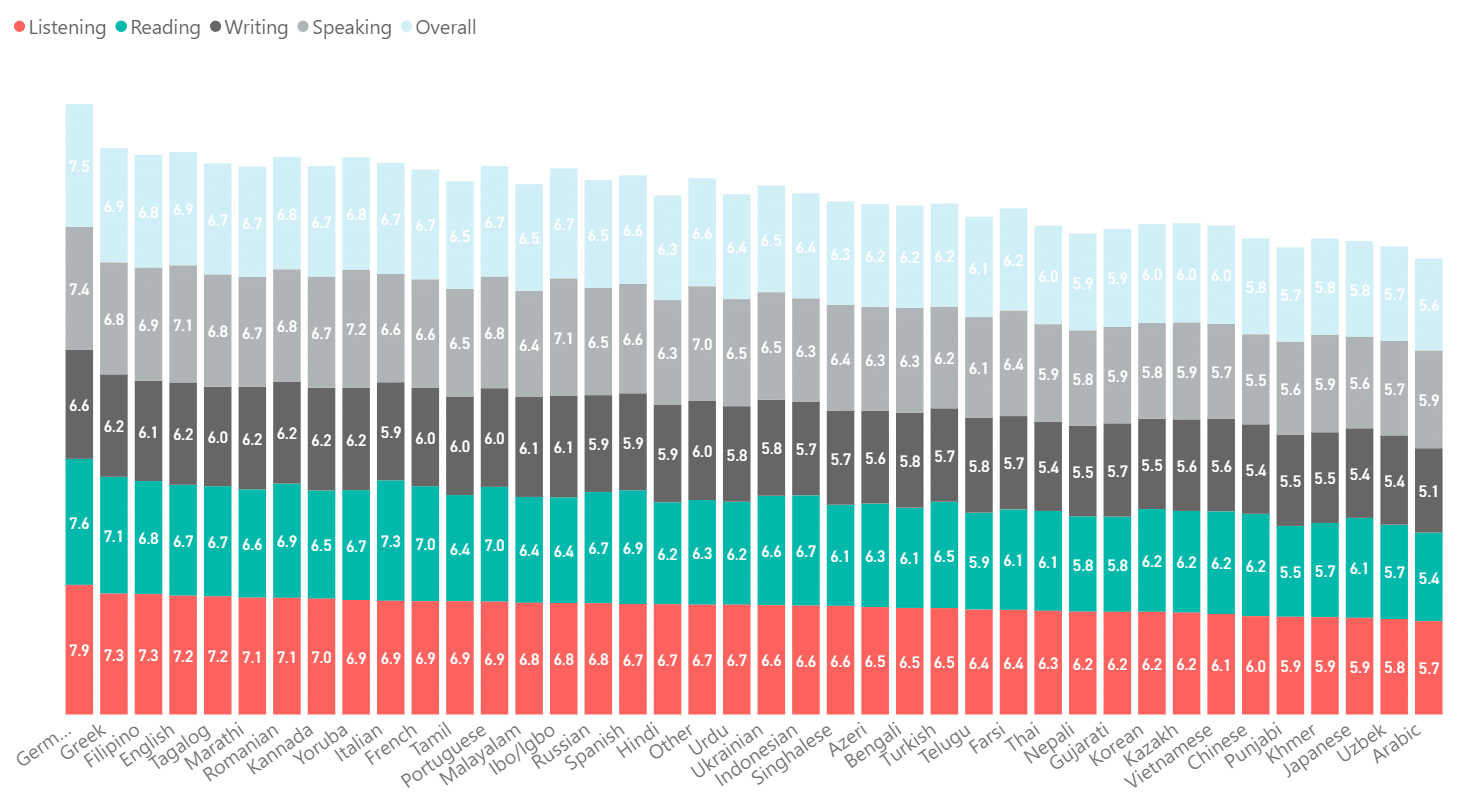
Mean band scores for the most common first languages (IELTS Academic 2018). Native English speakers were a distant fourth, with German native speakers leading the pack
Many supporters point to the correlations between EAP test scores and GPAs, but this correlation is not only unproven, but also logically flawed. If a high level of English guaranteed good grades, then all native speakers would graduate university with perfect marks. Clearly that’s not the case, because there are many factors involved in academic success (Picard, 2007):
“Academic success is influenced by a number of factors including professional experience, personal problems and motivation which are far greater predictors of academic success than a high IELTS score (Cotton & Conrow, 1998; Kerstjens & Nery, 2000; Kitson, 2005). Additionally, research has suggested that academic difficulties of international students are more often related to a “clash of educational cultures” than merely “poor English” (Ballard & Clanchy, 1997).”
And the same logic applies to using English language ability as a barrier to immigration. If fluent English makes you a good, useful, and productive member of society then we would have no native speakers who are criminals, or unemployed, or just lazy.
I wonder if the all of the administrators, and CEOs, and employees of these testing companies, and universities, and governments would be willing to bet their futures on passing these exams.
I think it’s vital that every institution, private or public, takes a moment to reflect on what it really means to have a future, and what it means to take it away from someone, just because the computer says no.